
Episodio 27 🐍⚙️
Episodio 27 🐍⚙️
Versiones nuevas de Prefect, Streamlit y más, manipulación de imágenes SAR, diferenciación de series temporales ruidosas, pandas paralelizado, y el curioso origen del p-valor

🚀 ¡Más versiones nuevas esta semana! Entre las novedades tenemos:
Prefect 2.0, un framework para crear flujos de procesado de datos, tira la casa por la ventana e introduce muchísimos cambios: decoradores mucho más sencillos para declarar grafos de tareas, todos los componentes liberados bajo Apache 2.0, y un nuevo motor de orquestación llamado Orion, entre otras.


Streamlit 1.8.0, con algunas mejoras de rendimiento introducidas después de la adquisición por parte de la empresa Snowflake. Streamlit es una solución para dashboards interactivos muy fácil de usar.
Stumpy 1.11.0, una biblioteca Python para análisis de series temporales utilizando una técnica llamada el perfil matricial (matrix profile), que trae una implementación de la distancia de Minkowski entre otras mejoras.


Y por último, primera versión pública de sarsen, una biblioteca Python para procesar imágenes de radar de apertura sintética (SAR). La ventaja distintiva del SAR es que atraviesa las nubes, cosa que los satélites de observación óptica no pueden hacer.


💡 Si en el episodio anterior hablábamos de SHAP, esta semana LinkedIn ha liberado FastTreeSHAP, una implementación de los mismos algoritmos de una manera mucho más eficiente.

También he descubierto en el Journal of Open Source Software una biblioteca llamada PyNumDiff, para diferenciación de series de tiempo ruidosas.
Y por último, si quieres aplicar reformateadores de código a tus notebooks tipo black e isort, ¡echa un vistazo a nbqa!


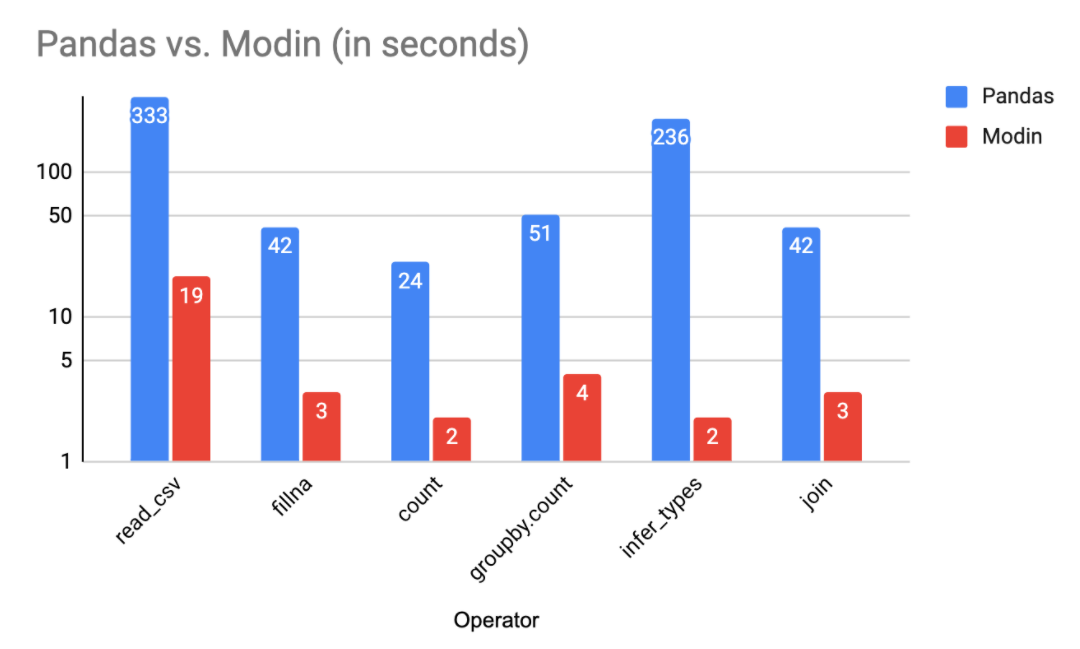
📚 En este artículo los creadores de Modin dan los detalles matemáticos de cómo paralelizaron más de 600 funciones de pandas, mejorando su rendimiento notablemente. ¡Con muchas ganas de probarlo!
Por otro lado, este artículo interactivo explica con todo lujo de detalles las diferencias entre precisión y exhaustividad (recall).

🤔 Cuando pides los datos de una publicación científica a veces te llevas respuestas bastante cuestionables, ¡incluso cuando la revista obliga! Mucho trabajo por hacer.



¿Tendrá algo que ver con que el valor p de corte que casi siempre se usa, 0.05, es totalmente arbitrario y tiene un origen más bien prosaico?


Y tú, ¿te has encontrado algún estudio justificando lo imposible con un valor p cerquísima de 0.05? ¡Cuéntanoslo en un comentario!